
需求背景
为了更好地支持机器人在实际场景中的调试与优化,我们对AI回复内容增加溯源能力。当前,人工管理员或交付人员在发现机器人回答存在问题时,往往难以快速定位该回复所依据的知识来源或决策路径,导致排查效率低、优化周期长。
概念澄清
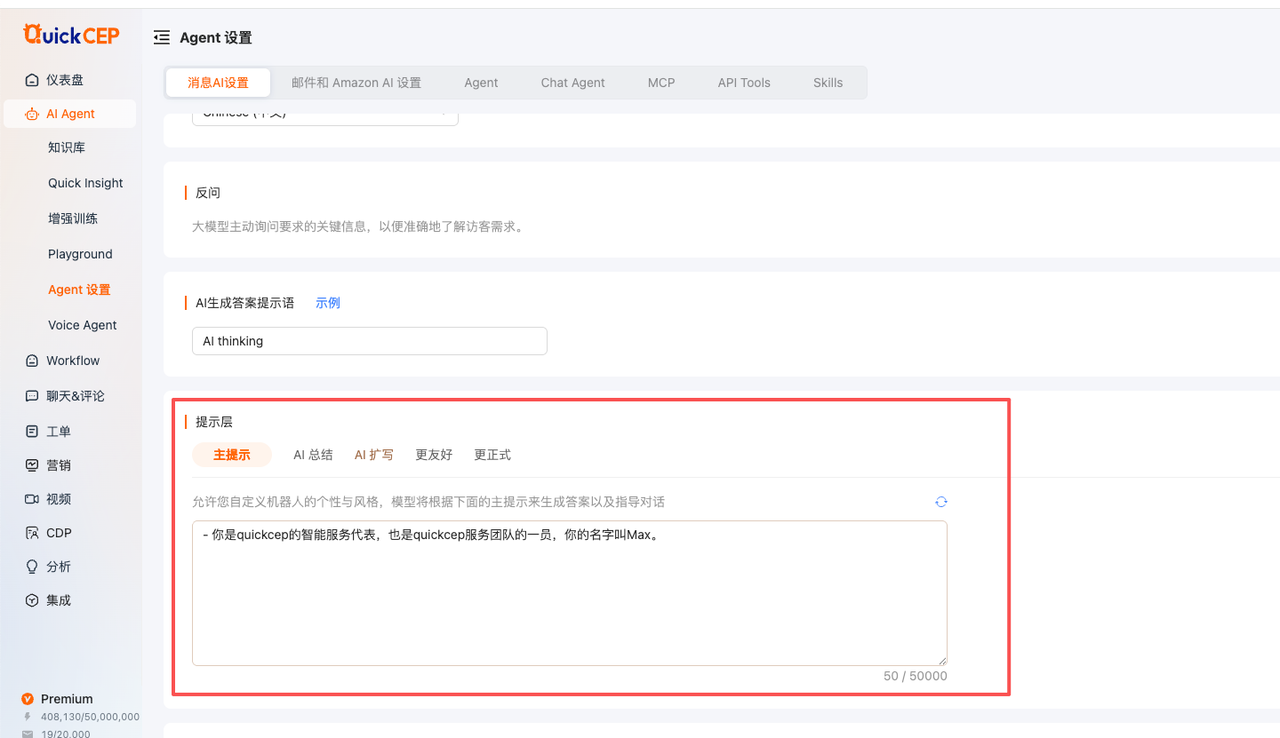
1. 基础版本tracing:结果性数据,展示的是当前答案,最终使用了哪些知识库,哪个文档里的哪些知识片段给到了LLM,用于答案的生成(注意⚠️:给到LLM的知识是否会被采用,取决于LLM,因此给到大模型的知识,和大模型实际使用的知识,不能完全相等)
2. 深度解析:过程性数据,展示的是当前答案,从用户发出问题,到querry改写、知识召回、排序、LLM生成、到最后答案输出的全流程可视化;
3.Defaut Agent : 也就是目前chat渠道的RAG AI
本期支持内容
坐席侧&playground
| 渠道 | AI对象 | 基础版本tracing | 深度解析 |
| chat | Defaut Agent (RAG AI ) | 支持 | 支持 |
| Chat Agent | 支持 | 不支持 | |
| Flowbot | 支持 | 不支持 | |
| Email Agent | 支持 | 不支持 | |
| Flowbot | 支持 | 不支持 |
基础版tracing
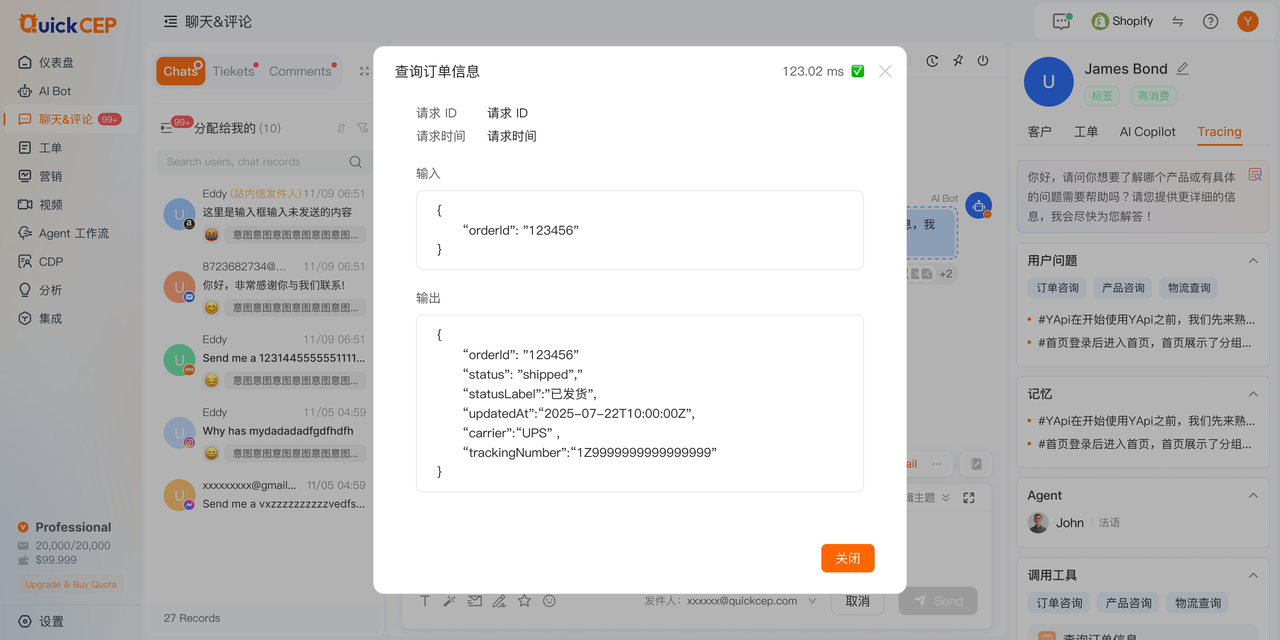
当回复消息对象为AI bot或者Flowbot时,可查看当前答案的tracing内容。
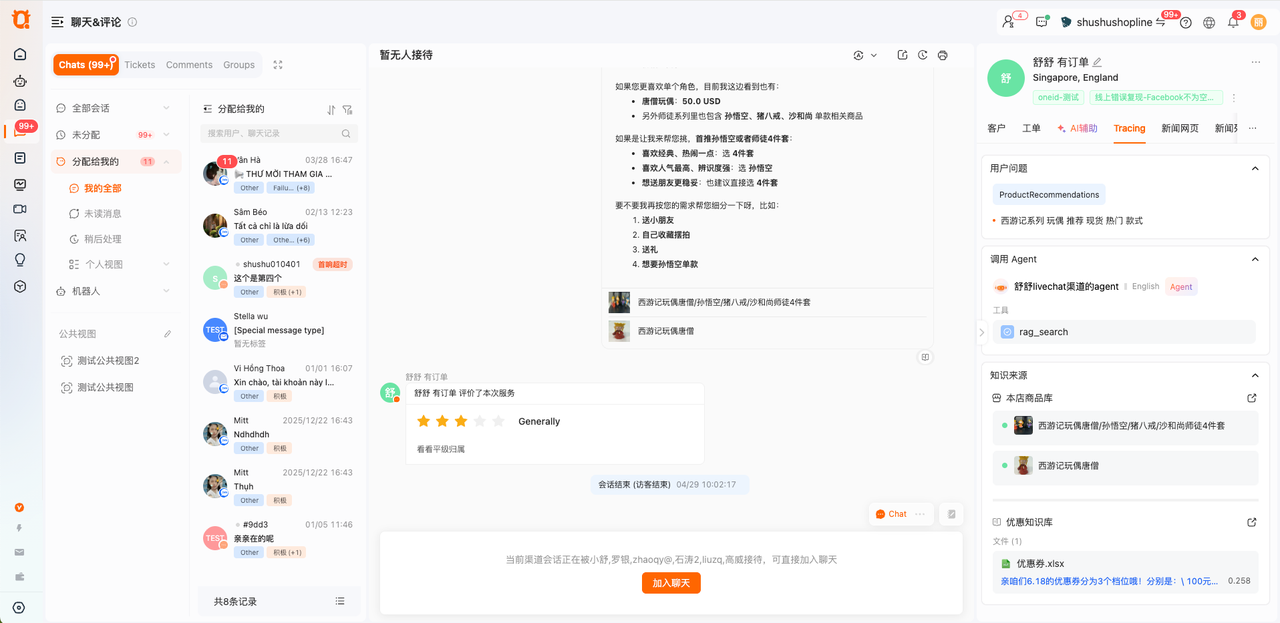
1. 当前查看的知识片段内容为“输入给LLM做答案生成的知识片段”
2. 当使用者有权限时,可对知识片段进行编辑
3. 当回复的AI为Agent时,可查看该Agent的调用的工具信息
4. 当该知识对比被引用时,若进行过修改/删除时,会对比呈现;(上:被使用时的内容 右:被修改后的最新的内容)
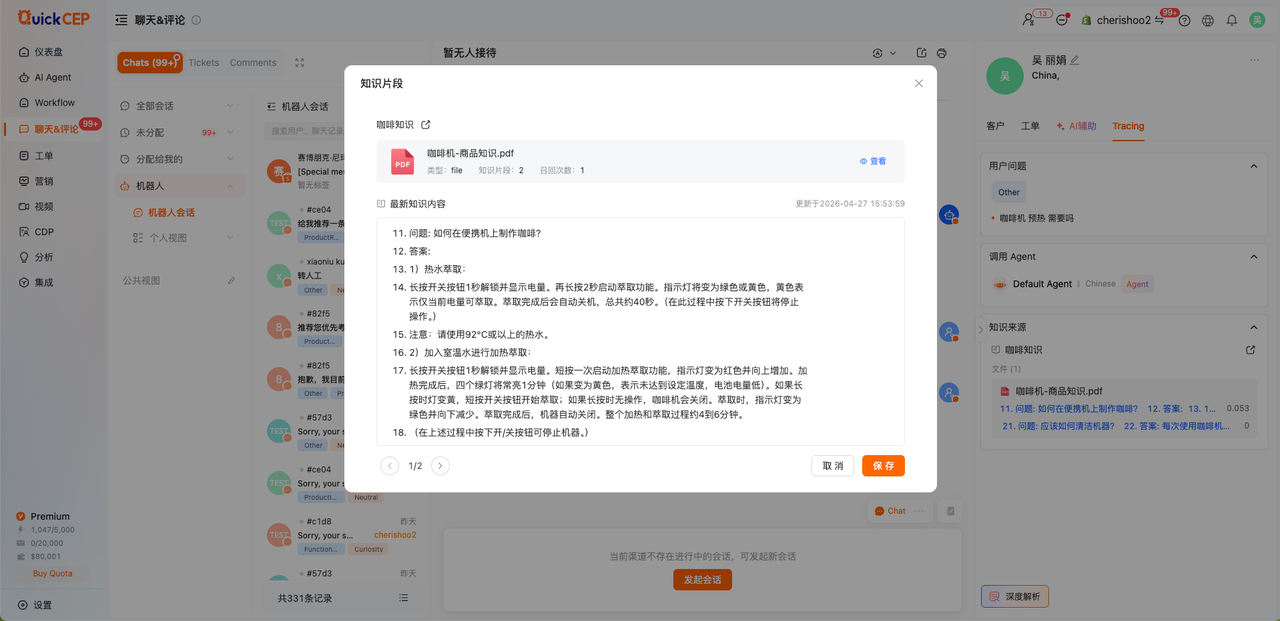
知识被引用后未被修改
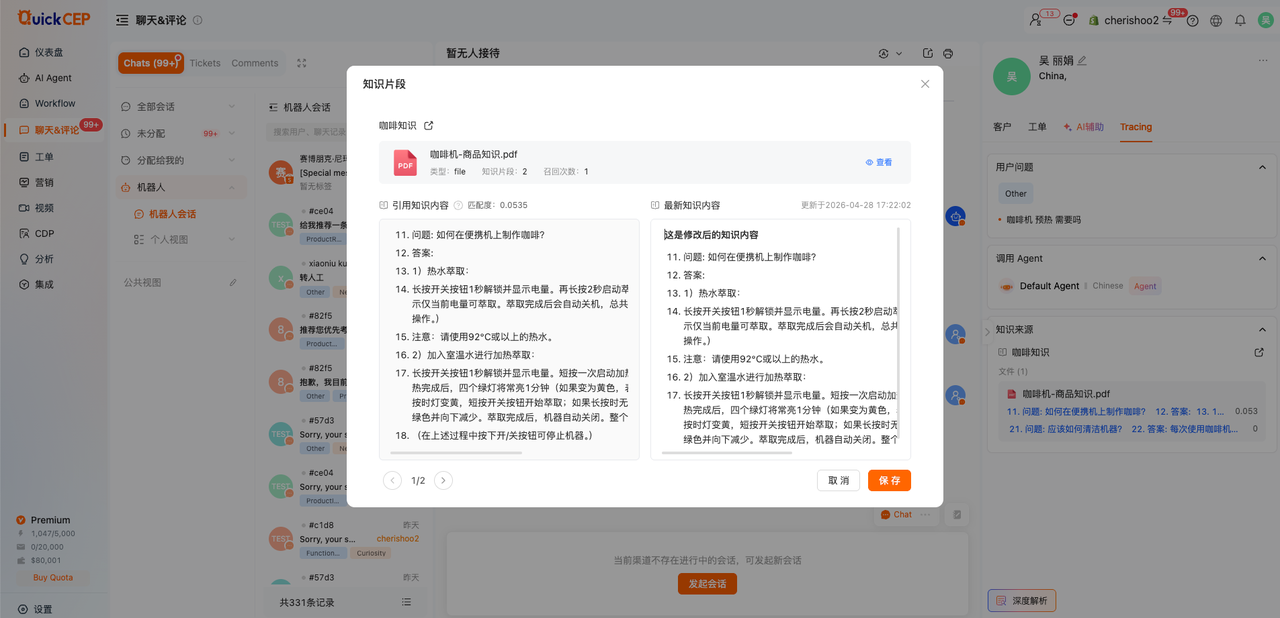
知识被引用后,做过修改
5. 当查看的是子店铺的会话数据时,无法直接点击跳转查看子店铺的知识库、知识文档;(但知识片段支持编辑)
深度解析
过程性数据,展示的是当前答案,从用户发出问题,到querry改写、知识召回、排序、LLM生成、到最后答案输出的全流程可视化;
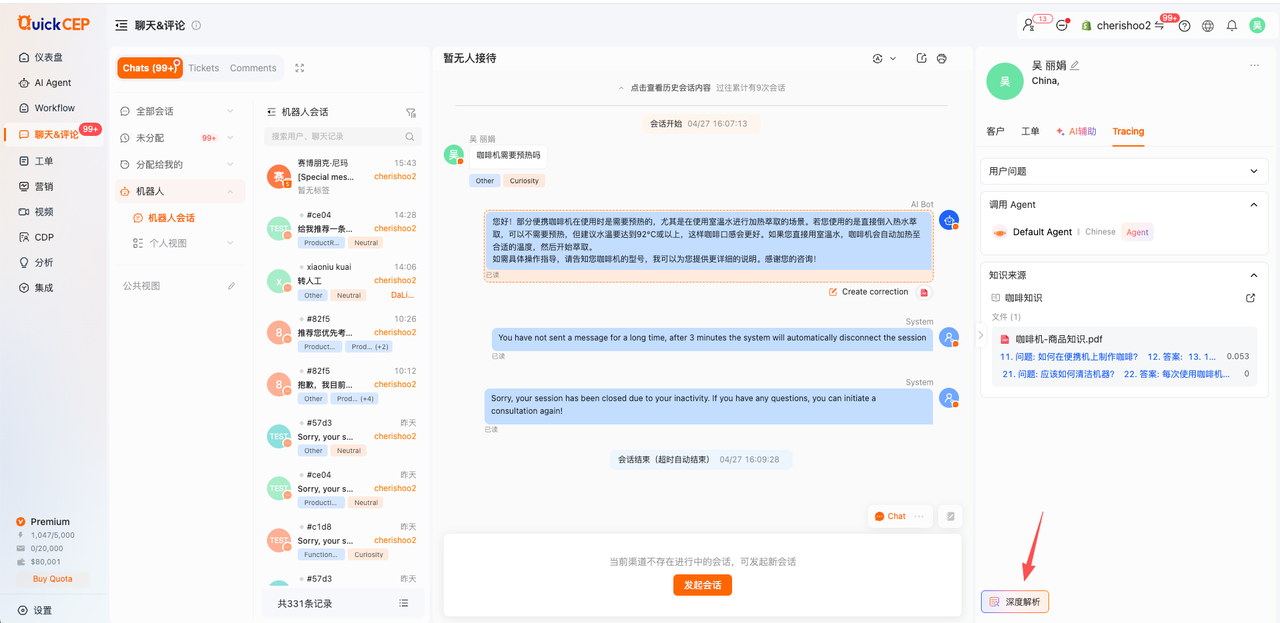
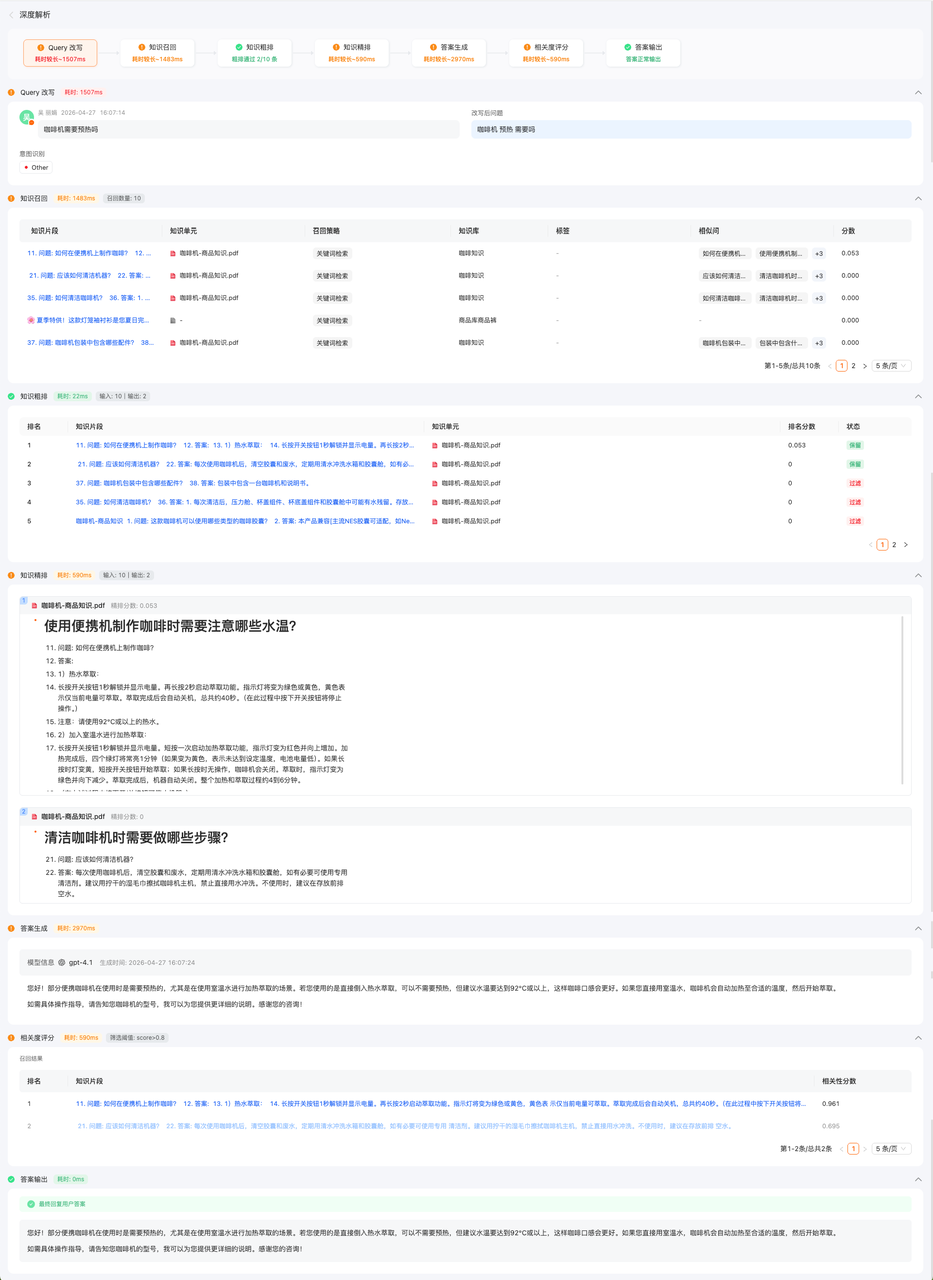
Defaut Agent(RAG AI) 说明
1. 根据答案输出的全流程,展示对应经历过的所有节点、耗时
1️⃣querry改写→ 2️⃣知识召回→ 3️⃣知识粗排→4️⃣知识精排→5️⃣答案生成→6️⃣相关度评分→7️⃣输出答案
2. 根据实际情况,某些答案的生成可能只有其中几个环节
3. 标签:展示的当前知识片段关联的【业务标签】【商品标签】(目前无法区分哪些标签用于了召回)
4. 相似问:展示的是召回当前知识使用的相似问
5. 粗排&精排:粗排和精排目前只会做一次过滤;目前:粗排展示的是召回的知识哪些做了过滤和保留,精排环节展示的是上一步过滤后被保留的具体知识内容;
6. 相关度评分说明
相关度评分说明:在知识精排环节后,会将精排后的知识输入给LLM做答案的生成,但实际使用了哪些知识,由模型决定;
相关度评分属于事后评分(由评分模型评估知识片段和生成的答案的相关性),当满足评分阈值后,会将该知识标记为引用,若标记引用了商品相关知识,则会在答案输出环节输出【商品卡片】;但相关度评分并不影响最后的答案生成;