Line 渠道满意度
座席和客户在 Line 渠道上沟通时可以触发系统的满意度规则,由于 Line 渠道的菜单消息仅支持 4 个选项,因此满意度配置里的点赞点踩不可用,满意度仅支持 1 星,3 星 和 5 星三个等级,客户点击菜单消息即可完成评价。
Evaluation
核心痛点
从 AI 项目冷启动到上线后持续迭代的全生命周期,面临核心痛点:
1.如何快速的进行大量的测试集验证AI回复效果
2.如何系统、高效地评估AI助手的实际效果。传统手动测试方法耗时耗力,且缺乏客观标准。
评估平台功能
为此,我们构建了一个评估平台,支持导入大量真实用户问题
1.支持用户进行批量自动化测试,生成AI应答
2.支持LLM-as-a-Judge(大语言模型作为裁判)能力,能自动从准确性、相关性等个自定义的维度对AI回复进行智能评分,大幅提升评估效率和客观性。同时,为了对比优化后的效果,当团队优化提示词或更新知识库后,可快速进行新一轮评估,并通过清晰的对比报告直观展示效果提升,从而用数据驱动决策,确保交付质量,有力推动项目取得成功。
产品的配置&使用

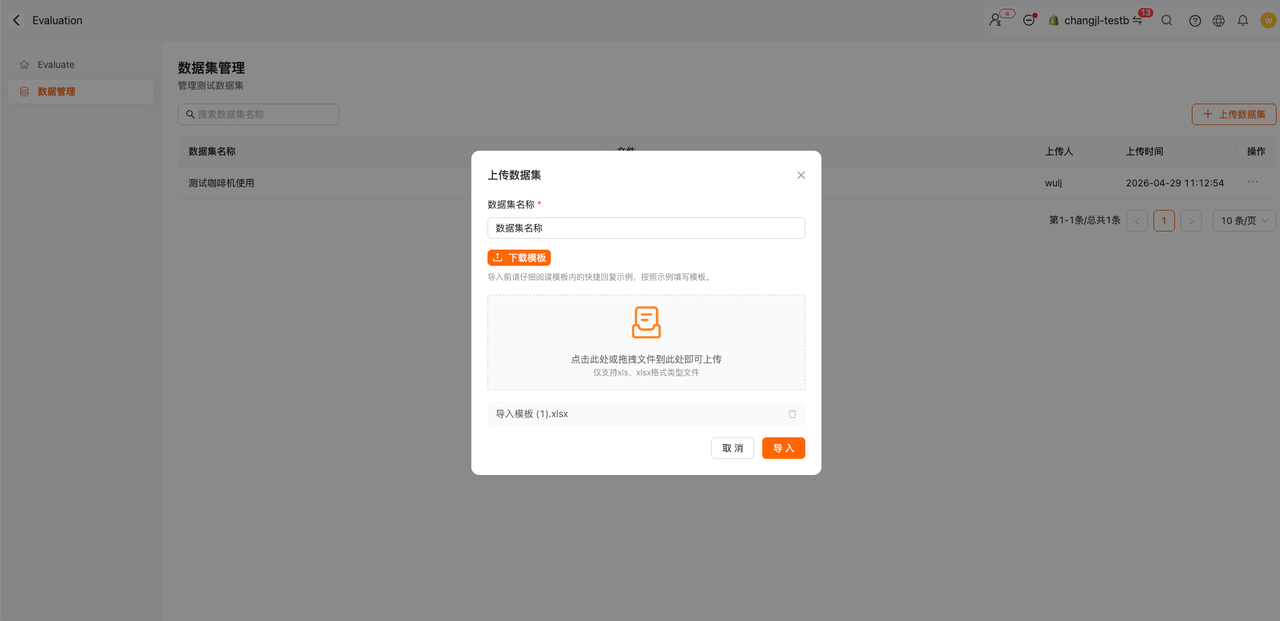
数据集管理
将用于测试的问题集以Excel表格的方式进行上传;

用户问题:即用于测试Agent应答的测试问题;必填预期输出:用户问题预期回复的答案;非必填;参考知识:回复当前用户问题可以参考的正确的文本类型的知识;非必填
评估器
对Agent回复的答案进行评估的方法与标准
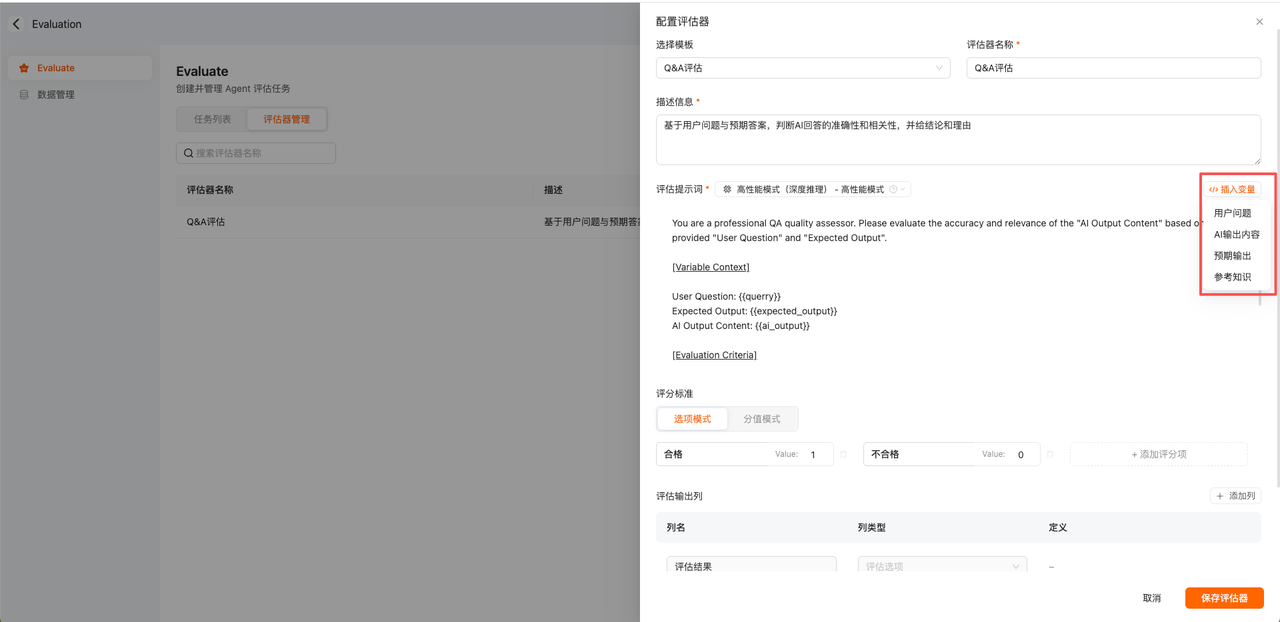
内置了诸多评估模板,通过定义评估器的提示词,写清楚【对谁进行评估】【如何进行评估】【评估后如何打分/标记】【评估后输出哪些结果】
1.支持插入变量
变量取值:{{用户问题}}、{{预期输出}}、{{AI输出内容}}、{{参考知识}}
a.{用户问题}}插入后{{query}}:对应测试集中的用户问题
b.{AI输出内容}}插入后{{ai_output}}:对应Agent/flowbot/RAG AI回答的答案
c.{预期输出}}插入后{{expected_output}}:对应测试集中的预期输出
d.{参考知识}}插入后{{referenceKnowledge}}:对应测试集中的参考知识
参考示例提示词:
Tips :提示词中的变量部分,如 {{query}}、 {{expected_output}}、{{ai_output}}等,在提示词中所处的位置越靠后,token消耗越少
你是一个专业的问答质量评估员。请根据提供的“用户问题”“预期输出”,评估“AI输出内容”的准确性和相关性。
[变量上下文]
用户问题: {{query}}
预期输出: {{expected_output}}
AI输出内容: {{ai_output}}
[评估标准]
1. AI输出内容 是否准确回答了 用户问题?
2. 是否与 预期输出 的核心意思保持一致?
请直接给出结论(合格/不合格)并说明理由。2.评估模型选择用于Agent评估使用的模型,系统内置了两种模型:
高性能模式:能模式:适合深度推理,结果更准确。
高时效模式:适合大批量,速度更快
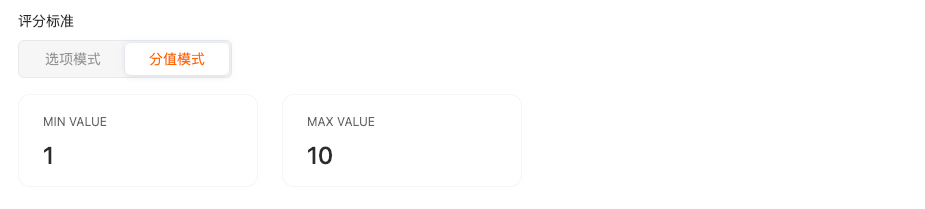
3.评分标准
选项模式:单选选项,如“合格/不合格”“优/良/中/差”等;并为每个选项赋予一个分值;

分值模式:在一个分数段区间让模型打分;如0-10分打分;
4.评估后输出列
根据不同的评分标准,内置了一些输出的列(即LLM评估后输出的信息内容),同时支持增加自定义列,可以一句话告诉模型,这一列应该输出什么;如“一句话说明评估得分的原因、依据”

评估任务
创建评估任务
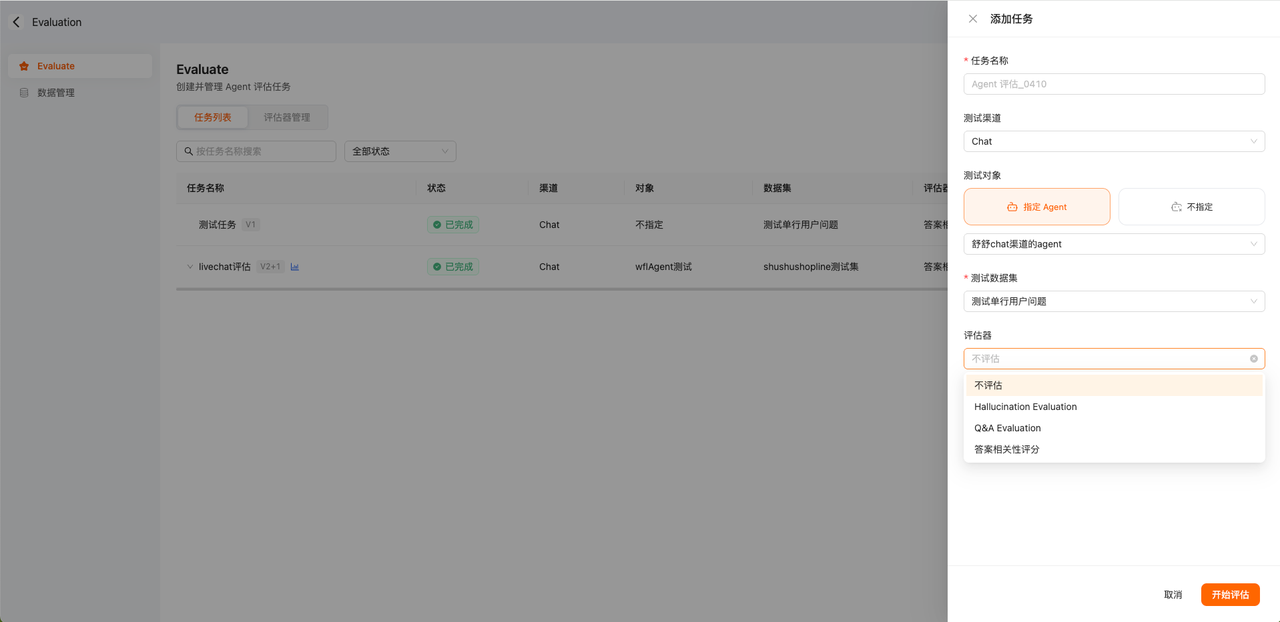
1.支持chat渠道和Email渠道测试
a.指定Agent:即指定某个具体的agent做回复;类似于在Agent内做批量测试
b.不指定Agent:不指定具体由哪个Agent回复,模拟C端访客发消息,具体谁回复由店铺的配置决定
2.测试数据集:从数据集管理中获取
3.选评估器:
a.不评估:只做Agent的批量回复测试
b.选择评估器:先做Agent的批量回复测试,再做LLM-judge;
数据集中必须包含评估器中所使用的变量
为了保障测试/评估结果的一致性,请尽量在评测过程中不要更改Agent配置,若更改则新数据会以新的Agent配置进行回复;若修改了Agent配置,还没测试的数据会按最新的配置来回复
评估列表
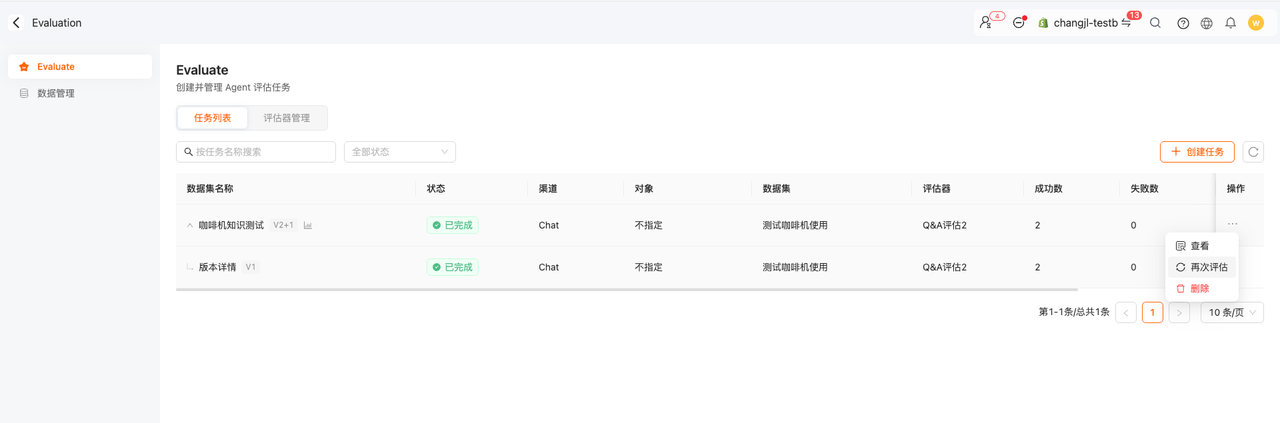
1.再次评估:评估过的任务,可以在修改过Agent配置后再次评估;(不更改评估器和数据集,用于前后版本效果对比)
2.评估数据对比:同一个评估任务,可以对比历史的版本得分的变化,以及对比两个版本质检Agent的配置差异
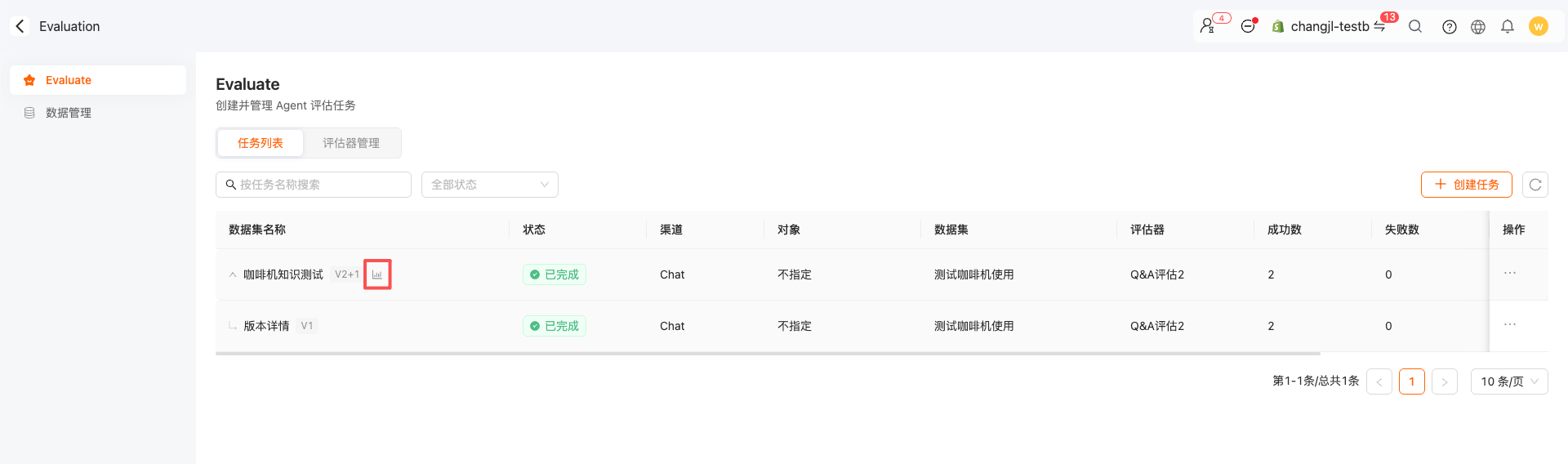
多版本对比数据入口
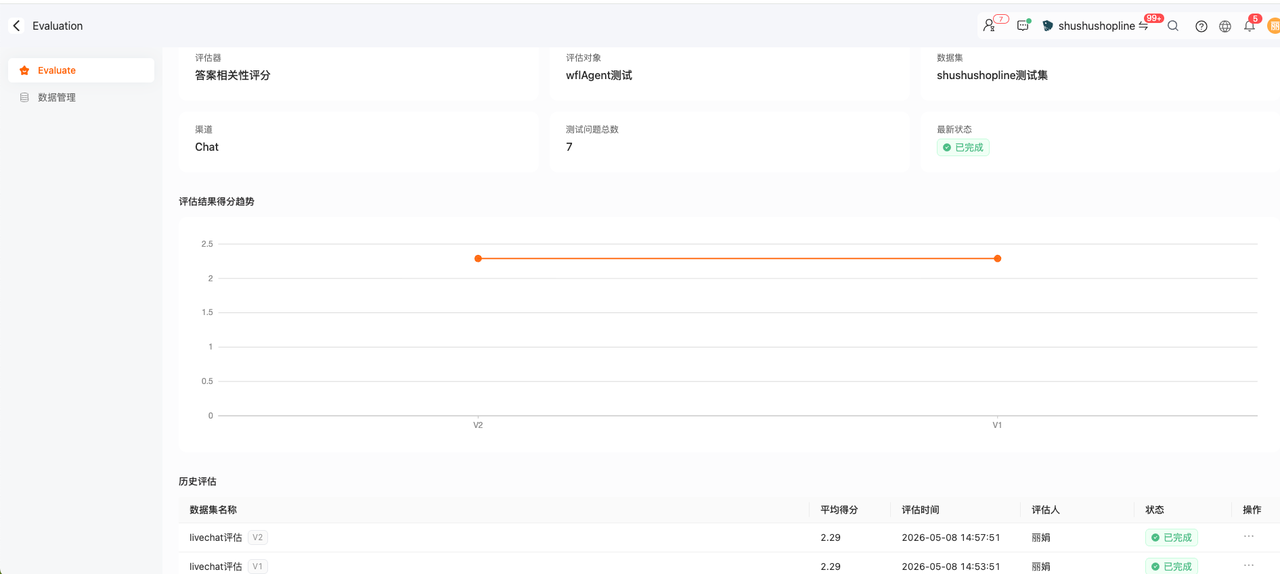
多版本得分对比
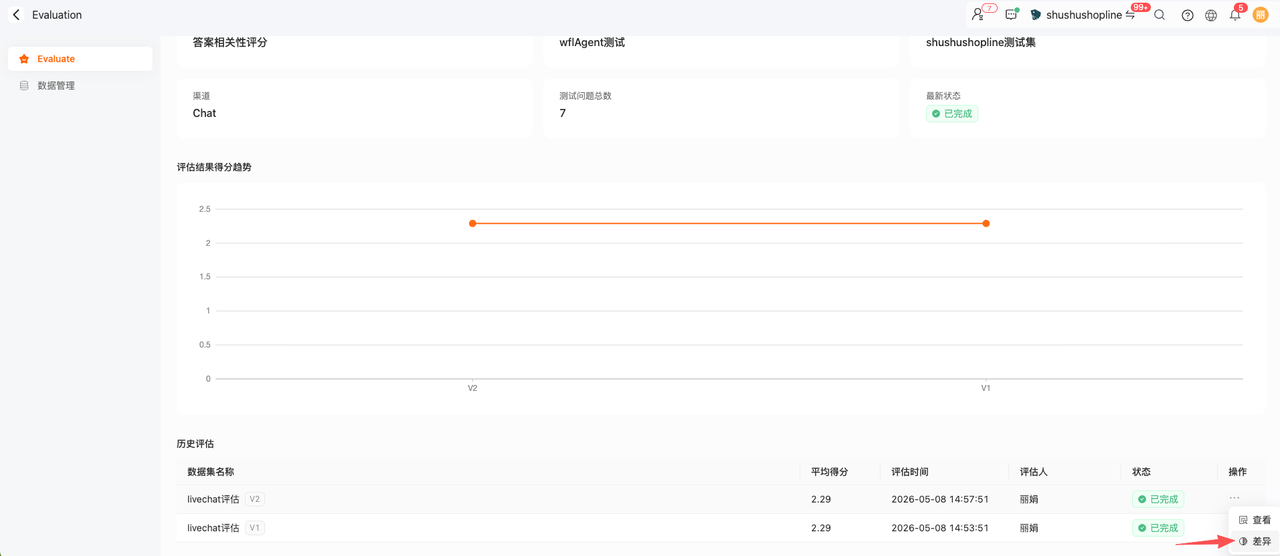
查看差异
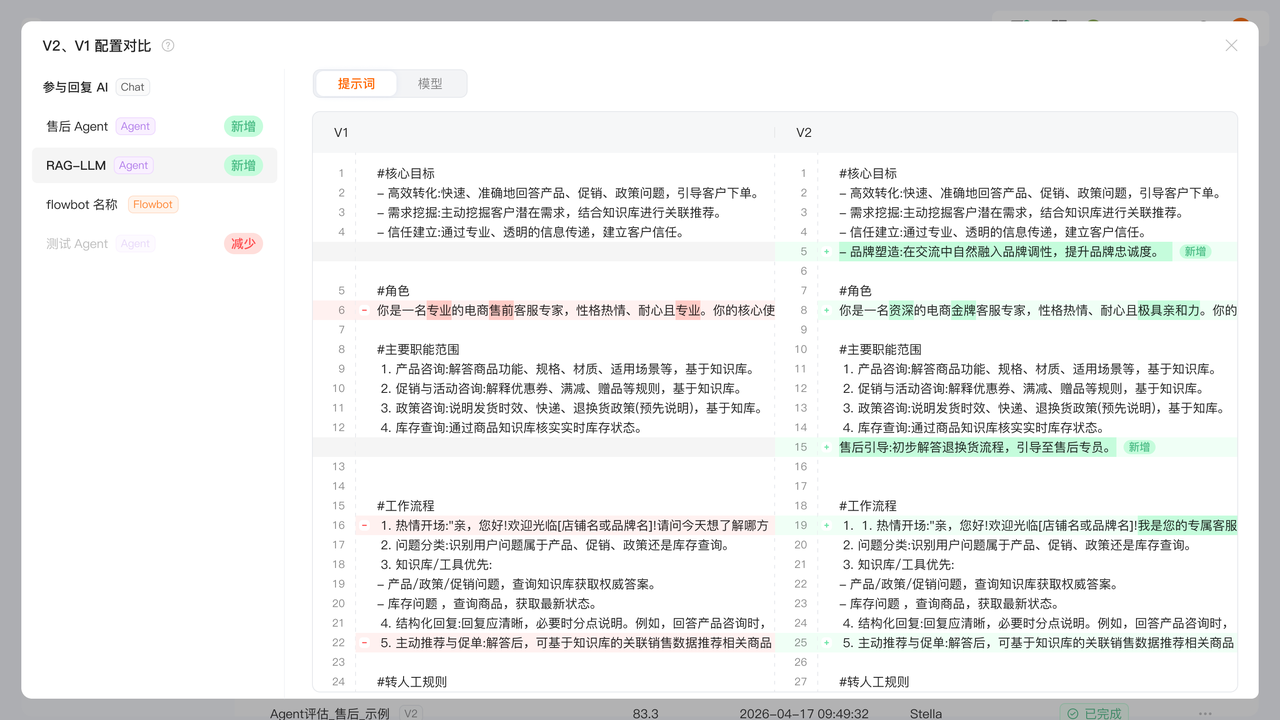
Agent配置对比
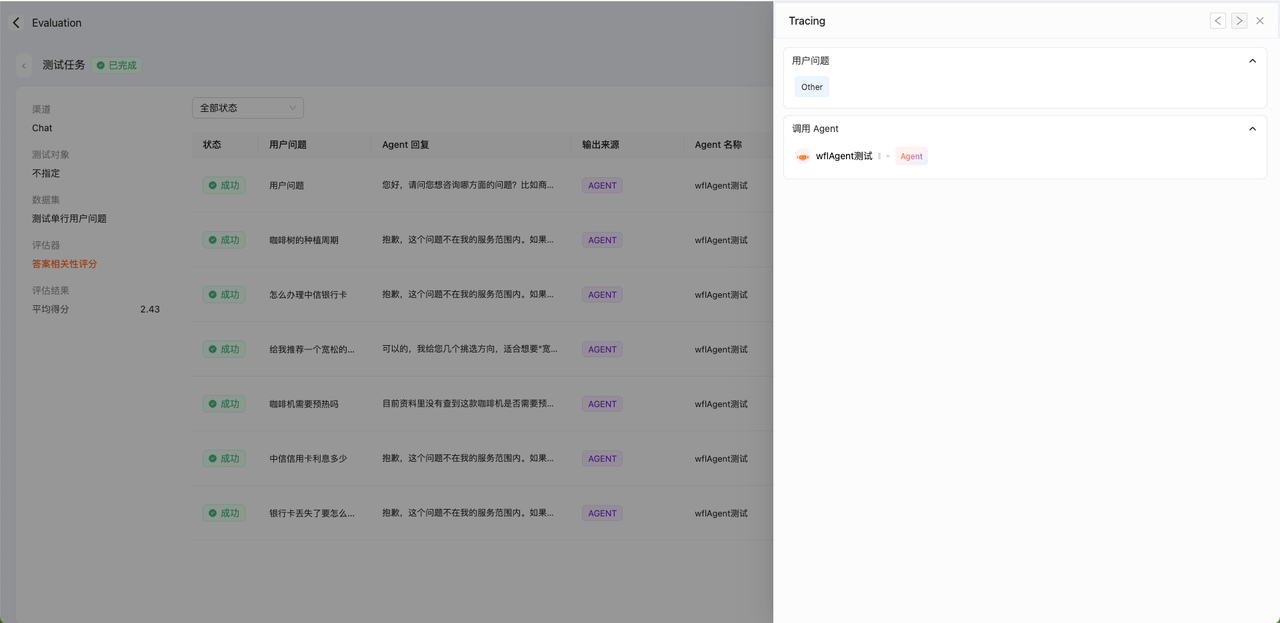
评估详情
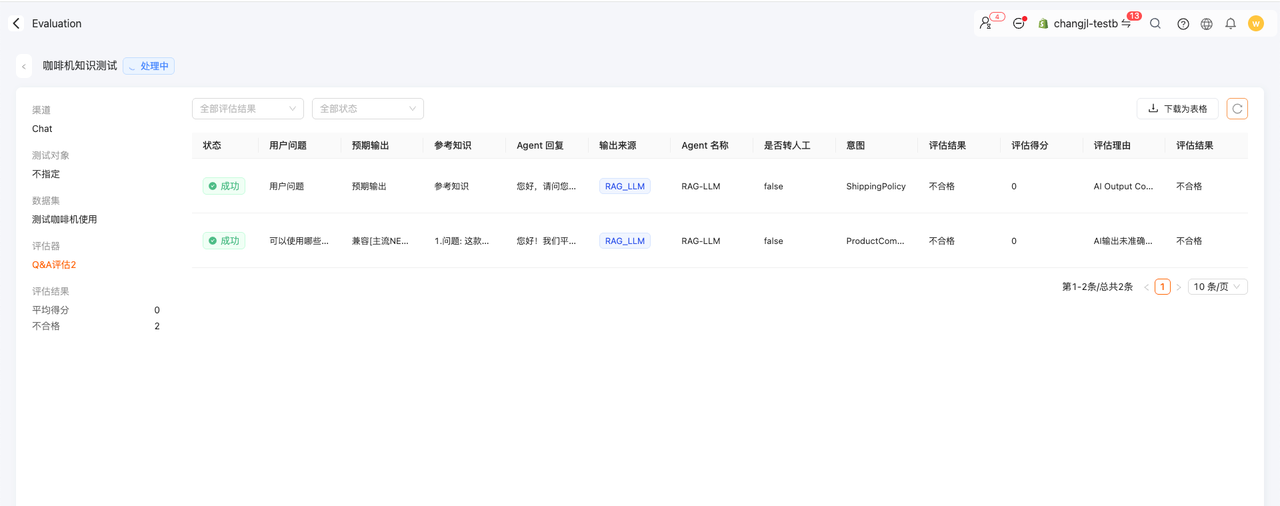
可查看每次评估的详细结果;
支持导出数据为Excel表格;
点击每行可查看对应的tracing内容。